
Contexte
Une marketplace sales-led
L’essentiel de l’activité commerciale de Muzzo est outbound. L’entreprise utilise la solution de Mantiks pour être informée dès qu’une entreprise qui correspond à ses critères publie une offre d’emploi sur un job board. La publication d’une telle offre est évidemment le signe d’un buying intent élevé.
Lorsqu’on détecte ce genre de signaux, il ne reste plus qu’à contacter les bonnes personnes dans ces entreprises pour avancer la proposition de valeur de Muzzo (mandater les meilleurs recruteurs simultanément sur le recrutement) et les y faire souscrire.
Problème : avalanche de csv
Contacter les bonnes personnes dans ces entreprises n’est pas trivial : il faut faire la navette entre plein d’outils (Sales Navigator, PhantomBuster, Kaspr, Google Sheets, …) avant de pouvoir fournir les coordonnées des Key Decision Makers (KDM) aux Sales de Muzzo.
Avant mon intervention, il fallait qu’un freelance fasse manuellement la navette entre tous les outils. Pluie de fichiers csv. Génération de leads démesurément coûteuse.
L’objectif
Automatiser au maximum la génération et l’enrichissement des leads.
Télécharger des csv d’un outil pour les charger dans un autre n’est pas très intéressant et ne requiert pas de créativité particulière.
Le cœur de ma mission consistait à construire une machine qui fasse transiter les leads à enrichir d’un outil à l’autre, en limitant au maximum les interventions humaines sur la chaîne.
Je ne pense pas qu’on puisse tout automatiser sans conséquences. Il y a un arbitrage à faire entre qualité des leads (et donc taux de conversion) et le temps (donc l’argent) que ça coûte. Choisir c’est renoncer.
La machine
Une ruche et des abeilles
J’ai mis au point une analogie pour expliquer ce que j’ai construit. Elle a deux avantages :
Elle permet de mieux appréhender le système (raisonnablement complexe) que j’ai construit
Elle peut se hisser au rang de framework — c’est le statut qu’elle a acquis dans mon esprit.
Ce que je veux dire par là, c’est qu’à l’avenir, dès qu’on me demandera de construire une machine du même type, c’est sur ce paradigme que je m’appuierai.
Voici sur quoi repose cette analogie :
Ruche → la base de données de prospection.
Alvéole → les lignes de la base de données.
Larve → le contenu d’une ligne de la base de données.
Fleurs → les différents outils d’enrichissement.
Abeilles → les automatisations qui naviguent entre les alvéoles de la ruche et les fleurs.
Le but : faire grossir les larves au sein des alvéoles et les donner à manger aux sales une fois arrivées à maturation.
Le process de A à Z
Le départ : Mantiks
Muzzo utilise Mantiks pour générer des rapports (i.e des automatisations qu’on configure à l’aide de différents filtres pour trouver les descriptifs de postes qui viennent d’être publiés).
Ces rapports sont construits manuellement (et continueront de l’être) à la discrétion des growths de l’équipe en fonction de la demande des sales.
C’est un premier moyen de piloter la volumétrie — on y reviendra plus loin.
Le contenu de ces rapports peut être téléchargé sous forme de csv (avant), ou bien envoyé sous forme de .json au webhook de notre choix (après).
Quoi qu’il en soit, c’est le contenu de ce rapport qui constitue le point de départ du process. Voici la forme qu’il peut prendre. Chaque ligne de ces rapports constitue une nouvelle alvéole dans notre ruche.
L’arrivée : les KDMs à contacter
Le point de départ : une entreprise avec un poste à pouvoir. Il s’agit donc d’une entreprise que Muzzo peut aider.
Pour y parvenir, il faut impérativement engager la discussion avec les bons decision makers. Typiquement, il vaut mieux contacter le CTO dans une entreprise qui cherche un développeur.
Mais c’est pas tout.
Lorsqu’on s’aperçoit qu’entreprise cherche un poste, il ne s’agit pas juste de trouver le bon decision maker, mais aussi ses informations de contact. Dans le meilleur des cas, c’est un numéro de téléphone, dans le pire des cas, un email.
C’est donc à ça que ressemble une “larve” arrivée à maturation : un (ou plusieurs) decision makers, avec au moins une coordonnée de contact pour les sales.
Entre le départ et l’arrivée
Voici, entre autres, les informations que Mantiks nous donne (cf. exemple) :
Le titre du poste à pourvoir
Le nom de l’entreprise qui recrute
Parfois son site internet
Parfois son url LinkedIn
La première étape consiste à déterminer le job title du bon decision maker à partir du titre du poste à pourvoir. On l’a dit, pour un software engineer, ce sera plutôt un CTO/Directeur Technique, pour un ingénieur en BTP, plutôt un RH/DRH/RRH.
Ensuite, pour trouver les personnes avec les job titles trouvés, dans la bonne entreprise, il faut qu’on puisse générer ce genre d’URL (copiez l’adresse et collez-la dans un document pour l’observer) de recherche Sales Navigator (l’outil de prédilection).
Pour trouver un ID Sales Navigator (e.g 2813941), il faut d’abord trouver l’URL LinkedIn de l’entreprise (e.g https://www.linkedin.com/company/gt-logistics-sas/).
On opère une disjonction de cas :
Soit elle est déjà présente dans le rapport Mantiks (parfait)
Soit elle n’est pas présente mais on a le site web. Dans ce cas, on peut le scraper pour y trouver l’éventuelle URL LinkedIn de l’entreprise en question.
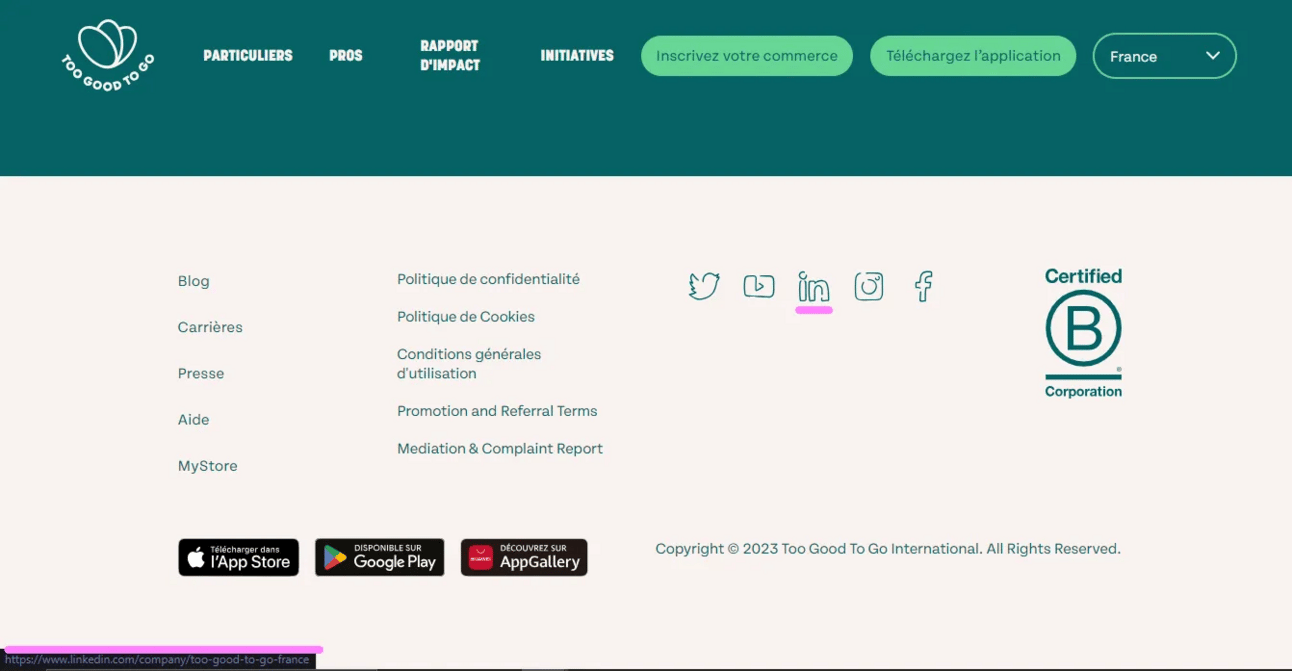
Comme ici sur le site de TooGoodToGo par exemple (et bien d’autres sites web, voilà pourquoi c’est pertinent de tenter le coup).
Soit on ne dispose que du nom de l’entreprise et on peut utiliser phantombuster pour tenter de retrouver l’URL LinkedIn de l’entreprise.

Pour tous les descriptifs de postes pour lesquels on aura trouvé l’URL LinkedIn de l’entreprise correspondante, on pourra alors utiliser ce phantom pour en récupérer les ID Sales Navigator.
On pourra ENFIN générer les URL de recherche Sales Navigator dont on parlait plus haut et se servir de ce phantom pour extraire la liste de decision makers pertinents pour l’offre d’emploi.
La sortie du phantom précédent servira d’entrée à cet ultime phantom dont la sortie est la liste des decision makers avec les URL de leurs profils LinkedIn.
Pour finir, pour tous les decision makers trouvés à l’étape précédente, on peut donner leurs URL de profils LinkedIn à manger à Kaspr. Une requête à l’API de Kaspr permettra (peut-être) de récupérer les numéros de téléphone et/ou les emails des decision makers.
Voici toutes les étapes par lesquelles passer afin de mener nos “larves” à maturité.
La stack technique
La ruche : Airtable
Airtable jour le rôle de base de données (et donc de ruche). Dans le jargon Airtable, on appelle :
Base → l’entièreté de la base de données
Table → une table de la base de données qui regroupe des enregistrements.
Enregistrements → les lignes d’une table, pour représenter des objets du même type.
Description de la ruche
Il y a une grande base pour gérer toute la chaîne de valeur — c’est notre ruche.
Trois tables dans cette base :
Job Posts → pour les offres d’emplois trouvées par Mantiks.

Companies → pour les entreprises correspondant aux offres d’emplois.

Contacts → pour tous les contacts des entreprises qui ont publié des offres.
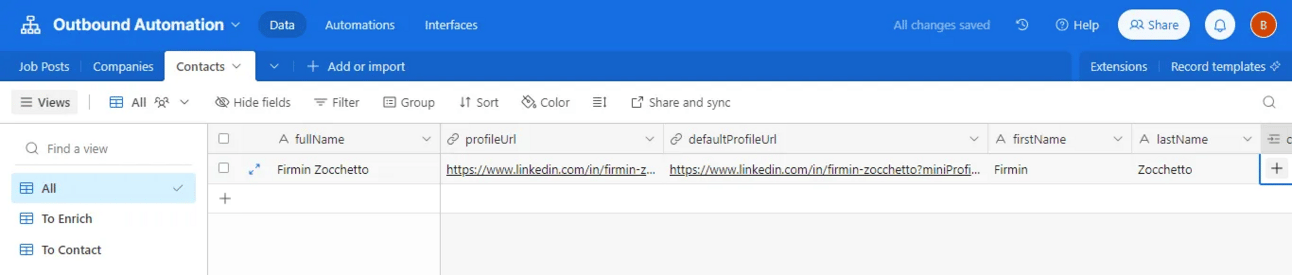



Des relations
On peut relier les enregistrements des différentes tables pour faire de la base une base de données relationnelles. C’est en partie pour ça que j’utilise Airtable.
Dans notre cas :
La table Job Posts est liée à la table Companies (et réciproquement bien sûr).
La table Contacts est liée aux tables Job Posts et Companies (et réciproquement).
On a lié Contacts à Job Posts et Companies, car tous les decision makers ne sont pas nécessairement pertinents pour tous les postes à pourvoir. Donc il est primordial de relier les decision makers à l’offre d’emploi pour laquelle on les a cherchés.
Les vues filtrées
C’est l’autre fonctionnalité qui a justifié d’utiliser Airtable : au sein d’une table, on peut créer une multitude de vues filtrées. Ces vues affichent une partie seulement de la table, en fonction des filtres appliqués dessus.
Par exemple, Search Company LinkedIn ID [PB] est une vue filtrée de la table Job Posts.

On a paramétré les filtres de cette vue pour qu’elle n’affiche que les offres d’emploi pour lesquelles l’URL LinkedIn de l’entreprise correspondante n’est pas vide ET pour lesquelles on n’est pas encore parti à la recherche du LinkedIn ID.
Voilà exactement ce qui se joue avec les vues filtrées. Les “larves” des “alvéoles” n’ont pas toutes besoin des mêmes “soins”. Certaines nécessitent une URL LinkedIn, d’autres, un ID Sales Navigator, etc.
En fonction de leurs besoins, les “alvéoles” et leurs “larves” remontent dans les vues filtrées qui leur correspondent. Dès lors, les “abeilles” les détectent et peuvent partir butiner les bonnes “fleurs” pour donner aux “larves” ce dont elles ont besoin.
Reprenons l’exemple du dessus : les workflows n8n (abeilles) comprennent que tous les enregistrements (larves) qui remontent dans la vue sont celles qui ont besoin d’un LinkedIn ID. cf. étape 4 : n8n se rendra auprès du bon phantom (fleur) pour faire sa demande d’ID SalesNav.
Bref, Airtable permet d’enrichir progressivement les enregistrements sans jamais les dupliquer. Il suffit à n8n de venir regarder à intervalles de temps réguliers ce qui est remonté dans chacune des vues filtrées.
Ça semble peu de choses, mais les implications sont majeures. On peut fonctionner de manière synchrone. C’est-à-dire que tous les workflows n8n peuvent tourner en même temps, grâce à des déclencheurs horaires.
Certes, il faut une URL LinkedIn avant d’avoir un LinkedIn ID, mais comme les enregistrements ne remontent pas dans la vue “SalesNav ID” avant d’avoir une URL LinkedIn, les enregistrements seront traités dans l’ordre, mais sans avoir précisé d’ordre de traitement.
Récapitulatif des raisons d’utiliser Airtable :
Base de données relationnelle
Vues filtrées
API aux rate limits élevées
Les abeilles : n8n
n8n est un outil d’automatisation (similaire à Zapier et Make) qui permet de faire naviguer des données entre différents outils grâce à leurs API respectives (et traiter les données qu’on fait transiter au milieu). cf. contexte, c’est l’outil idéal pour ce qu’on s’apprête à faire.
Métaphoriquement, chaque workflow n8n est une abeille qui navigue entre une alvéole et une fleur pour butiner la ressource requise par la larve.

Voici par exemple le workflow qui regarde dans une des vues filtrées de la ruche s’il y a des sites webs à crawler (les Job Posts pour lesquels on a un site web mais pas d’URL LinkedIn d’entreprise). S’il y en a, on prend le premier, on se rend sur son site web, on regarde si une URL LinkedIn s’y cache.
Si c’est le cas, on enregistre l’URL trouvée dans “l’alvéole” (i.e la ligne de la table) lui correspondant, et, automatiquement, le Job Post sort de la vue filtrée.
Les fleurs : Mantiks, Google Sheet, Phantombuster, Kaspr
Mantiks
On l’a dit plus haut, Mantiks est la “fleur originelle”, c’est d’elle que n8n tire tous les Job Posts à enrichir.
Google Sheet
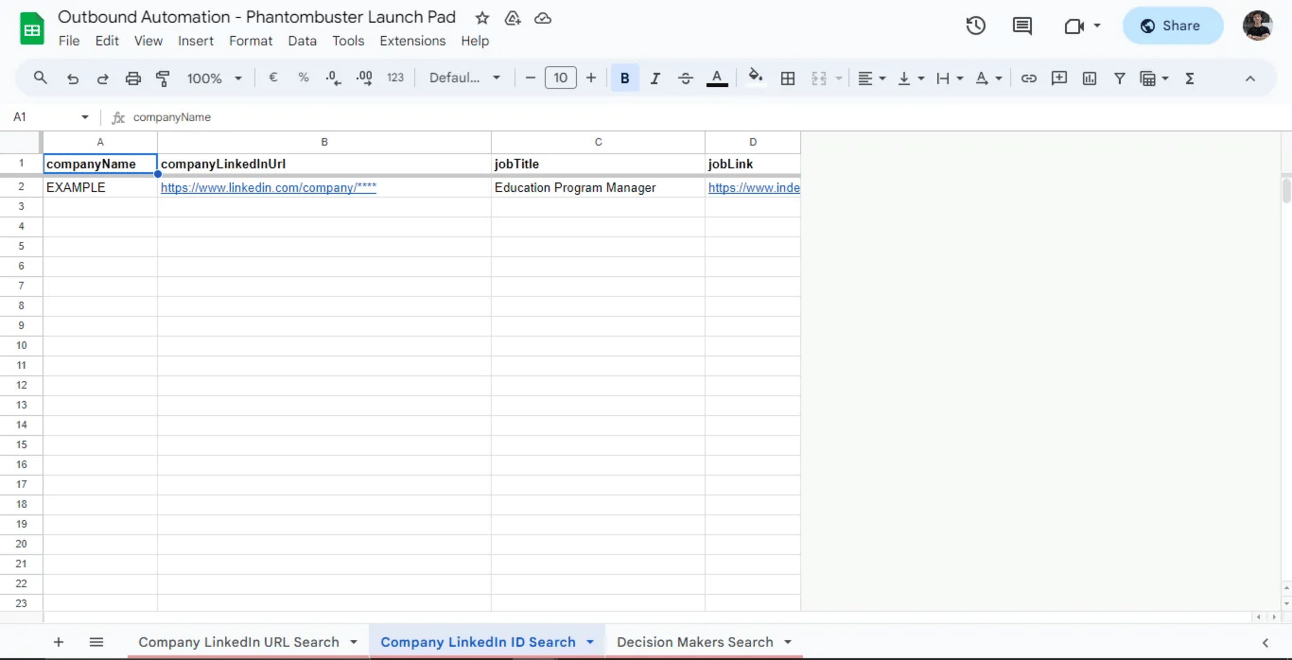
La seule utilité de la Google Sheet, c’est de servir de file de traitement à Phantombuster. En effet, un phantom est construit de telle manière à pouvoir ingérer les lignes d’une spreadsheet.
Il traitera les lignes de la spreadsheet dans l’ordre dans lequel elles sont arrivées (i.e du haut vers le bas). À une sheet de la spreadsheet correspond un phantom qui s’en sert comme donnée d’entrée.
Le rôle des abeilles n8n vis-à-vis de la spreadsheet est simplement d’en alimenter les trois rampes de lancement :
Company LinkedIn URL Search → pour les job posts tels que l’entreprise associée n’a pas encore d’URL LinkedIn (et pour laquelle le website crawling n’a rien donné).
Company LinkedIn ID Search → pour toutes les entreprises possédant une URL LinkedIn et pour lesquelles on cherche désormais un Sales Navigator ID.
Decision Maker Search → pour toutes les URL de recherche de decision makers Sales Navigator générées, dont on veut extraire les résultats.
PhantomBuster
Après avoir ingéré les données de la sheet qui lui correspond, un phantom va effectivement partir en quête de l’information demandée.
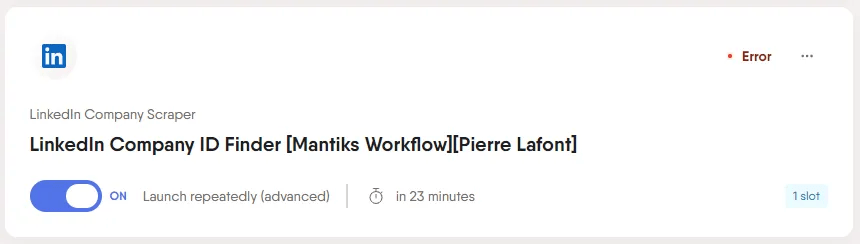
Ce phantom, par exemple, prend les données de la sheet Company LinkedIn ID Search pour scraper la page LinkedIn de l’entreprise et en extraire l’ID.
À chaque fois que le phantom trouve un nouveau résultat, il en informe la bonne “abeille” (i.e le bon workflow) dans n8n pour qu’elle vienne récupérer l’information et la mettre dans la “ruche” (i.e Airtable). J’ai utilisé la fonctionnalité webhook de PhantomBuster.
Kaspr
Kaspr est l’ultime fleur à laquelle n8n butine. C’est grâce à Kaspr qu’on trouve des coordonnées de contact pour un maximum de decision makers, à partir de leurs URL LinkedIn.


Volumétrie
L’objet de cette section est d’estimer le volume de contacts maximal qu’il serait possible de contacter tous les mois avec un compte PhantomBuster Starter et un compte Sales Navigator grâce à cette automatisation.
Les automatisations trouvent toujours leurs limites, et plutôt rapidement lorsqu’on joue avec LinkedIn. Le réseau social n’est pas du tout tolérant à cet l’égard, il faut donc être très prudent. C’est ce qui justifie les calculs à venir.
Attention, c’est technique : vous pouvez vous arrêtez là si les considérations de volumétrie ne vous intéressent pas vraiment.
Paramètres
De tous les outils utilisés, il sera possible d’en ignorer plusieurs dans le cadre de cette étude :
Mantiks qui ne semble pas avoir de limites en termes d’appels à API
Airtable qui autorise 5 appels/s à son API (plus qu’il n’en faut)
n8n qui n’a tout simplement pas de limites
Kaspr qui fonctionne au nombre de crédits.
Ainsi, pour la suite de notre estimation, il suffira de considérer :
PhantomBuster (sa limite de
20h/moisde temps de calcul avec le plan Starter) conjointement à LinkedIn/Sales Navigator (limites en termes de profils/entreprises visités chaque jour).Attention, les fréquences maximales sont valables lorsqu’un seul phantom est en train de tourner. Si on a trois phantoms qui tournent simultanément en utilisant un unique compte (c’est notre cas), les limites baissent.
Kaspr, non pas à l’aune des rate limits mais des taux de succès lors de la recherche d’informations de contact (~85% pour les mails et 40% pour les téléphones).
Suppositions
On peut faire abstraction de la limite imposée par PhantomBuster dans un premier temps, car une fois la limite atteinte, PhantomBuster s’arrêtera simplement de tourner. Alors que si les limites Sales Navigator sont atteintes, on risque le bannissement du compte. Dit autrement, notre facteur limitant se trouve dans le tableau du dessus, pas dans “
20h/mois".On est en mesure de créer une infinité de rapports Mantiks pour alimenter le pipe à l’amont.
Une unique URL de recherche Sales Navigator retourne deux profils (on a paramètré PhantomBuster ainsi, en supposant qu’au-delà, les profils ne sont pas assez pertinents). Il faut par ailleurs savoir que les 2 profils tiennent sur une unique page de recherche Sales Navigator.
Calcul
Sachant que la conversion d’URL de profils est limitée à 150/j et qu’une unique URL de recherche SalesNav retourne déjà 2 profils, inutile d’exporter les résultats de plus de 75 recherches Sales Nav par jour, donc inutile de scraper plus de 75 entreprises par jour, donc inutile de chercher les URL LinkedIn de plus de 75 entreprises par jour.
Par ailleurs, on l’a dit : 3 phantoms tournent simultanément sur un même compte Sales Navigator.
Donc on peut raisonnablement (← pifomètre) baisser les limites à 100 conversions de profils par jour, 50 recherches Sales Navigator par jour, 50 scraping d’entreprises par jour et 50 recherches d’URL LinkedIn par jour.
In fine :
Le LinkedIn URL Finder tourne sur 50 entreprises par jour i.e pendant 30 * 30s = 25min
Le Company Scraper, sur 50 entreprises aussi i.e pendant 30 * 30s = 25min
Le Sales Navigator Search Export, sur 50 URL de recherche = 50 pages i.e 50 * 30s = 25min
Le Sales Navigator URL Converter, sur 100 profils par jour i.e 100 * 6s = 10min
On fait donc tourner PhantomBuster ~1h25/j.
Il est temps de réintroduire la contrainte PhantomBuster. Comme on est limité à 20h/mois de temps de calcul, PhantomBuster s’arrêterait le 14 du mois. Donc PhantomBuster tournerait pendant 14j et sortirait 100 profils tous les jours où il tourne, soit 1400 profils/mois.
Or puisque Kaspr affiche un taux de succès de 40% sur les numéros de téléphone, ce sont finalement :
~1200 profils qu’il serait possible de contacter tous les mois par mail.
~560 profils qu’il serait possible de contacter tous les mois par téléphone.
Evidemment, il faut aligner la cadence des workflows n8n pour que PhantomBuster ne tourne le moins possible à vide. C’est simple, il suffit que la cadence de n8n soit légèrement supérieure à celle de PhantomBuster pour que ce dernier ait toujours une entrée à traiter.
C’est facile de faire grimper les volumes
Passer au plan supérieur de PhantomBuster (80h/mois) et immédiatement multiplier par 2.15 le nombre de profils enrichis (donc 2580 profils à contacter par mail, 1204 profils par téléphone). Il resterait encore ($80h - 30 * 1h25$) = 37h30min de temps de calcul PhantomBuster.
Utiliser un autre compte Sales Navigator en parallèle du premier pour consommer les 37h30min de temps de calcul restantes ce qui correspond à — grosso modo — un peu moins que doubler ce qu’on a déjà (42,5h ~ 37,5h)
Bref, avec rien qu’une licence Sales Navigator en plus et le plan supérieur de PhantomBuster, nous aurions tous les mois :
5000 profils à contacter par mail
2200 profils à contacter par téléphone